

Creating a great machine learning system is an art.
There are a lot of things to consider while building a great machine learning system. But often it happens that we as data scientists only worry about certain parts of the project.
Most of the time that happens to be modeling, but in reality, the success or failure of a Machine Learning project depends on a lot of other factors.
A machine learning pipeline is more than just creating Models
It is essential to understand what happens before training a model and after training the model and deploying it in production.
This post is about explaining what is involved in an end to end data project pipeline. Something I did learn very late in my career.
1. Problem Definition
This one is obvious — Define a problem.
And, this may be the most crucial part of the whole exercise.
So, how to define a problem for Machine learning?
Well, that depends on a lot of factors. Amongst all the elements that we consider, the first one should be to understand how it will benefit the business.
That is the holy grail of any data science project. If your project does not help business, it won’t get deployed. Period.
Once you get an idea and you determine business compatibility, you need to define a success metric.
Now, what does success look like?
Is it 90% accuracy or 95% accuracy or 99% accuracy.
Well, I may be happy with a 70% prediction accuracy since an average human won’t surpass that accuracy ever and in the meantime, you get to automate the process.
Beware, this is not the time to set lofty targets; it is the time to be logical and sensible about how every 1 percent accuracy change could affect success.
For example: For a click prediction problem/Fraud application, a 1% accuracy increase will boost the business bottom line compared to a 1% accuracy increase in review sentiment prediction.
Not all accuracy increases are created equal
2. Data
There are several questions you will need to answer at the time of data acquisition and data creation for your machine learning model.
The most important question to answer here is: Does your model need to work in realtime?
If that is the case, you can’t use a system like Hive/Hadoop for data storage as such systems could introduce a lot of latency and are suitable for offline batch processing.
Does your model need to be trained in Realtime?
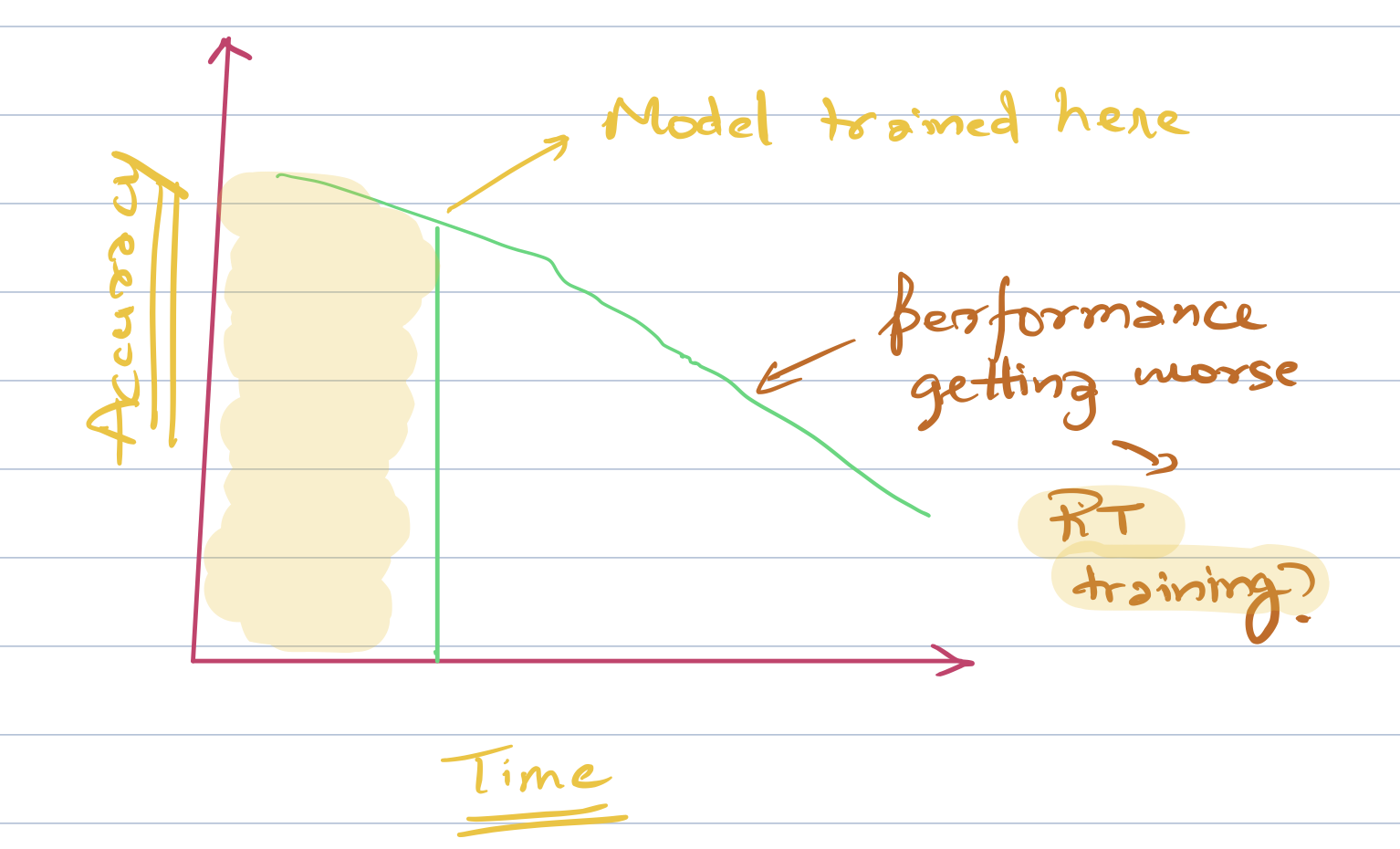
If the performance of your ML model decreases with time as in the above figure, you might want to consider Real-time training. RT training might be beneficial for most of the click prediction systems as internet trends change rather quickly.
Is there an inconsistency between test and train data?
Or in simple words — do you suspect that the production data comes from a different distribution from training data?
For example: In a realtime training for a click prediction problem, you show the user the ad, and he doesn’t click. Is it a failure example? Maybe the user clicks typically after 10 minutes. But you have already created the data and trained your model on that.
There are a lot of factors you should consider while preparing data for your models. You need to ask questions and think about the process end to end to be successful at this stage.
3. Evaluation
/https%3A%2F%2Fmiro.medium.com%2Fmax%2F1920%2F0*39N92nM_YCQCyhAM.png)
How will we evaluate the performance of our Model?
The gold standard here is the train-test-validation split.
Frequently making a train-validation-test set, by sampling, we forgot about an implicit assumption — Data is rarely ever IID(independently and identically distributed).
In simple terms, our assumption that each data point is independent of each other and comes from the same distribution is faulty at best if not downright incorrect.
For an internet company, a data point from 2007 is very different from a data point that comes in 2019. They don’t come from the same distribution because of a lot of factors- internet speed being the foremost.
If you have a cat vs. dog prediction problem, you are pretty much good with Random sampling. But, in most of the machine learning models, the task is to predict the future.
You can think about splitting your data using the time variable rather than sampling randomly from the data. For example: for the click prediction problem you can have all your past data till last month as training data and data for last month as validation.
The next thing you will need to think about is the baseline model.
Let us say we use RMSE as an evaluation metric for our time series models. We evaluated the model on the test set, and the RMSE came out to be 4.8.
Is that a good RMSE? How do we know? We need a baseline RMSE. This could come from a currently employed model for the same task. Or by using some simple model. For Time series model, a baseline to defeat is last day prediction. i.e., predict the number on the previous day.
For NLP classification models, I usually set the baseline to be the evaluation metric(Accuracy, F1, log loss) of Logistic regression models on Countvectorizer(Bag of words).
You should also think about how you will be breaking evaluation in multiple groups so that your model doesn’t induce unnecessary biases.

Last year, Amazon was in the news for a secret AI recruiting tool that showed bias against women. To save our Machine Learning model from such inconsistencies, we need to evaluate our model on different groups. Maybe our model is not so accurate for women as it is for men because there is far less number of women in training data.
Or maybe a model predicting if a product is going to be bought or not given a view works pretty well for a specific product category and not for other product categories.
Keeping such things in mind beforehand and thinking precisely about what could go wrong with a particular evaluation approach is something that could definitely help us in designing a good ML system.
4. Features

Good Features are the backbone of any machine learning model. And often the part where you would spend the most time. I have seen that this is the part which you can tune for maximum model performance.
Good feature creation often needs domain knowledge, creativity, and lots of time.
On top of that, the feature creation exercise might change for different models. For example, feature creation is very different for Neural networks vs. XGboost.
Understanding various methods for Feature creation is a pretty big topic in itself. I have written a post here on feature creation. Do take a look:The Hitchhiker’s Guide to Feature ExtractionAn exhaustive look at feature engineering techniquestowardsdatascience.com
Once you create a lot of features, the next thing you might want to do is to remove redundant features. Here are some methods to do thatThe 5 Feature Selection Algorithms every Data Scientist should knowBonus: What makes a good footballer great?towardsdatascience.com
5. Modeling

Now comes the part we mostly tend to care about. And why not? It is the piece that we end up delivering at the end of the project. And this is the part for which we have spent all those hours on data acquisition and cleaning, feature creation and whatnot.
So what do we need to think while creating a model?
The first question that you may need to ask ourselves is that if your model needs to be interpretable?
There are quite a lot of use cases where the business may want an interpretable model. One such use case is when we want to do attribution modeling. Here we define the effect of various advertising streams(TV, radio, newspaper, etc.) on the revenue. In such cases, understanding the response from each advertisement stream becomes essential.
If we need to maximize the accuracy or any other metric, we will still want to go for black-box models like NeuralNets or XGBoost.
Apart from model selection, there should be other things on your mind too:
- Model Architecture: How many layers for NNs, or how many trees for GBT or how you need to create feature interactions for Linear models.
- How to tune hyperparameters?: You should try to automate this part. There are a lot of tools in the market for this. I tend to use hyperopt.
6. Experimentation

Now you have created your model.
It performs better than the baseline/your current model. How should we go forward?
We have two choices-
- Go into an endless loop in improving our model further.
- Test our model in production settings, get more insights about what could go wrong and then continue improving our model with continuous integration.
I am a fan of the second approach. In his awesome third course named Structuring Machine learning projects in the Coursera Deep Learning Specialization, Andrew Ng says —
“Don’t start off trying to design and build the perfect system. Instead, build and train a basic system quickly — perhaps in just a few days. Even if the basic system is far from the “best” system you can build, it is valuable to examine how the basic system functions: you will quickly find clues that show you the most promising directions in which to invest your time.”
One thing I would also like to stress is continuous integration. If your current model performs better than the existing model, why not deploy it in production rather than running after incremental gains?
To test the validity of your assumption that your model being better than the existing model, you can set up an A/B test. Some users(Test group)see your model while some users(Control) see the predictions from the previous model.
You should always aim to minimize the time to first online experiment for your model. This not only generated value but also lets you understand the shortcomings of your model with realtime feedback which you can then work on.
Conclusion
Nothing is simple in Machine learning. And nothing should be assumed.
You should always remain critical of any decisions you have taken while building an ML pipeline.
A simple looking decision could be the difference between the success or failure of your machine learning project.
All Rights Reserved for Rahul Agarwal

One Comment