

Setting the right course and steering responsibly
Setting the right course
Rapid adoption of complex machine learning (ML) models in recent years has brought with it a new challenge for today’s companies: how to interpret, understand, and explain the reasoning behind these complex models’ predictions. Treating complex ML systems as trustworthy black boxes without sanity checking has led to some disastrous outcomes, as evidenced by recent disclosures of gender and racial biases in GenderShades¹.
As ML-assisted predictions integrate more deeply into high-stakes decision-making, such as medical diagnoses, recidivism risk prediction, loan approval processes, etc., knowing the root causes of an ML prediction becomes crucial. If we know that certain model predictions reflect bias and are not aligned with our best knowledge and societal values (such as an equal opportunity policy or outcome equity), we can detect these undesirable ML defects, prevent the deployment of such ML systems, and correct model defects.

Our mission at Intuit is powering prosperity around the world. To help small businesses and individuals increase their odds for success, in the last few years Intuit has been infusing AI and ML across its platform and solutions. As data scientists at Intuit, we have a unique privilege and power to develop ML models that make decisions that affect people’s lives. With that power, we also bear the responsibility to make sure our models are held in the highest standards, and are not discriminating in any manner. “Integrity without compromise” is one of Intuit’s core values. As we grow as an AI/ML-driven organization, machine intelligibility has become a priority for Intuit’s AI/ML products.
This year, Intuit hosted an Explainable AI workshop (XAI 2019) at KDD 2019. We gleaned many valuable learnings from this workshop that we will start to incorporate in our product and service strategies.
Understanding the current state of interpretability
Interpretability is an active area of research and the description provided below is meant to provide a high level summary of the current state of the field. Interpretability methods fall into two major categories based on whether the model being interpreted is: (a) black box (unintelligible) or (b) glass box (intelligible). In the following section, we will explain and compare each of the approaches. We will also describe how we can use intelligible models to better understand our data. Then we will review a method to detect high-performing intelligible models for any use case (Rashomon curves). Finally, we will compare local and global explanations and feature-based vs. concept-based explanation.
Black box:
Black box interpretability methods attempt to explain already-existing ML models without taking into account the inner workings of the model (i.e., the learned decision functions). This class of interpretability methods is model-agnostic and can be integrated easily with a wide variety of ML models, from decision tree-based models to complex neural networks² ³ ⁴ ⁵. Applying black box interpretability does not require any changes in the way ML practitioners create and train the models. For this reason, black box interpretability methods enjoy wider adoption among ML practitioners. Black box interpretability methods are also referred to as “post-hoc” interpretability, as they can be used to interrogate ML models after training and deployment without any knowledge of the training procedures. Examples of black box interpretability methods include LIME², Shapley⁶, Integrated Gradients⁷, DeepLIFT⁸, etc. Post-hoc model interpretations are a proxy for explanations. The explanations derived in this manner are not necessarily guaranteed to be human-friendly, useful, or actionable.
Glass box:
A glass box approach with intelligible ML models requires that models be “interpretable“ upfront (aka “pre-hoc”)⁹ ¹⁰. The advantage of this approach is the ease with which ML practitioners can tease out model explanations, detect data and/or label flaws, and in some cases, edit the model’s decisions if they do not align with practitioner values or domain knowledge. , Senior Principal Researcher at Microsoft Research and one of KDD XAI 2019’s keynote speakers, demonstrated how his team built a highly accurate, intelligible, and editable ML model based on generalized additive models (GAMs)¹¹ and applied it to mortality prediction in pneumonia cases¹². This version, named also GA2M ( or “GAM on steroids”) is optimized by gradient boosting instead of the cubic splines in the original version, and achieves results comparable to modern ML models (such as random forest or gradient-boosted trees).
Using Intelligible models
Caruana shared how his team uses intelligible models to better understand and correct their data. For example, the intelligible model learned the rule that patients with pneumonia who have a history of asthma have a lower risk of dying from pneumonia than the general population. This rule is counterintuitive, but reflects a true pattern in the training data: patients with a history of asthma who presented with pneumonia usually were admitted not only to the hospital but directly to the Intensive Care Unit. The aggressive care received by asthmatic pneumonia patients was so effective that it lowered their risk of dying from pneumonia in comparison with the general population. Because the prognosis for these patients is better than average, models trained on the data incorrectly learn that asthma lowers mortality risk, when in fact asthmatics have much higher risk (if not aggressively treated).
If simpler, intelligible models can learn counterintuitive association — such as, having asthma implies lower pneumonia risk — more complex neural network-based algorithms can probably do the same. Even if we can remove the asthma bias from the data, what other incorrect things were learned? This is the classic problem of statistical confounding: when a variable (in our case, treatment intensity) is associated with both the dependent and independent variable, causing a spurious association. The treatment intensity is influenced by the variable of asthma, and in turn reduces the risk of mortality.
This observation illustrates the importance of model intelligibility in high stakes decision-making. Models that captured true but spurious patterns or idiosyncrasies in the data — such as false association in the pneumonia example or societal biases — could generate predictions that lead to undesirable consequential outcomes such as mistreating patients. Current ML models are trained to minimize prediction errors on the training data and not on aligning with any human intuition and concepts, so there’s no guarantee that models will align the human’s values. More often than not, ML models trained on human-curated datasets will reflect the defect or bias in the data¹³. An intelligible model allows these defects to surface during model validation.
Currently, only a small subset of algorithms — namely decision tree-based models and generalized additive models (GAMs) — are intelligible. Decision tree-based models and GAMs are not used in ML applications (such as computer vision, natural language processing, and time series predictions) because the best possible versions of these models currently do not perform at the state-of-the-art-level of complex deep neural network-based models.
Detecting high-performing intelligible models for any use case
When we’re able to choose between equally-performing intelligible and black box models, the best practice is to choose the intelligible one¹⁴. How can we know whether a high-performing intelligible model exists for a particular application? Cynthia Rudin, Professor of Computer Science at Duke University and the Institute of Mathematical Statistics (IMS) Fellow 2019 (also a KDD XAI 2019 panelist) proposed a diagnostic tool, called the “Rashomon Curve,”¹⁵ that helps ML practitioners answer this question.
Let’s first define a few terms. “Rashomon effect” denotes the situation in which there exist many different and approximately-equally accurate descriptions to explain a phenomenon. The term “Rashomon effect” is derived from a popular Japanese film (Rashomon) known for a plot that involves various characters providing self-serving descriptions of the same incident. A “Rashomon set,” defined over the hypothesis space of all possible models in a model class, is a subset of ML models that have training performance close to the best model in the class. The “Rashomon ratio” is the cardinality of the Rashomon set divided by the cardinality of all possible models (with varying levels of accuracy). Thus, “Rashomon ratio” is defined uniquely for each ML task/dataset pair. When the Rashomon ratio is large, there exist several equally highly accurate ML models to solve that ML task. Some of these highly accurate models within the Rashomon set might have desirable properties such as intelligibility and it may be worthwhile to find such models. Thus, Rashomon ratio serves as an indicator of the simplicity of the ML problem.
In her KDD 2019 keynote talk, Rudin introduced the “Rashomon curve”¹⁵ (see figure below), a diagnostic curve connecting the log Rashomon ratio of hierarchy of model classes with increasing complexity as a function of the empirical risk (the error rate bound on the model classes).
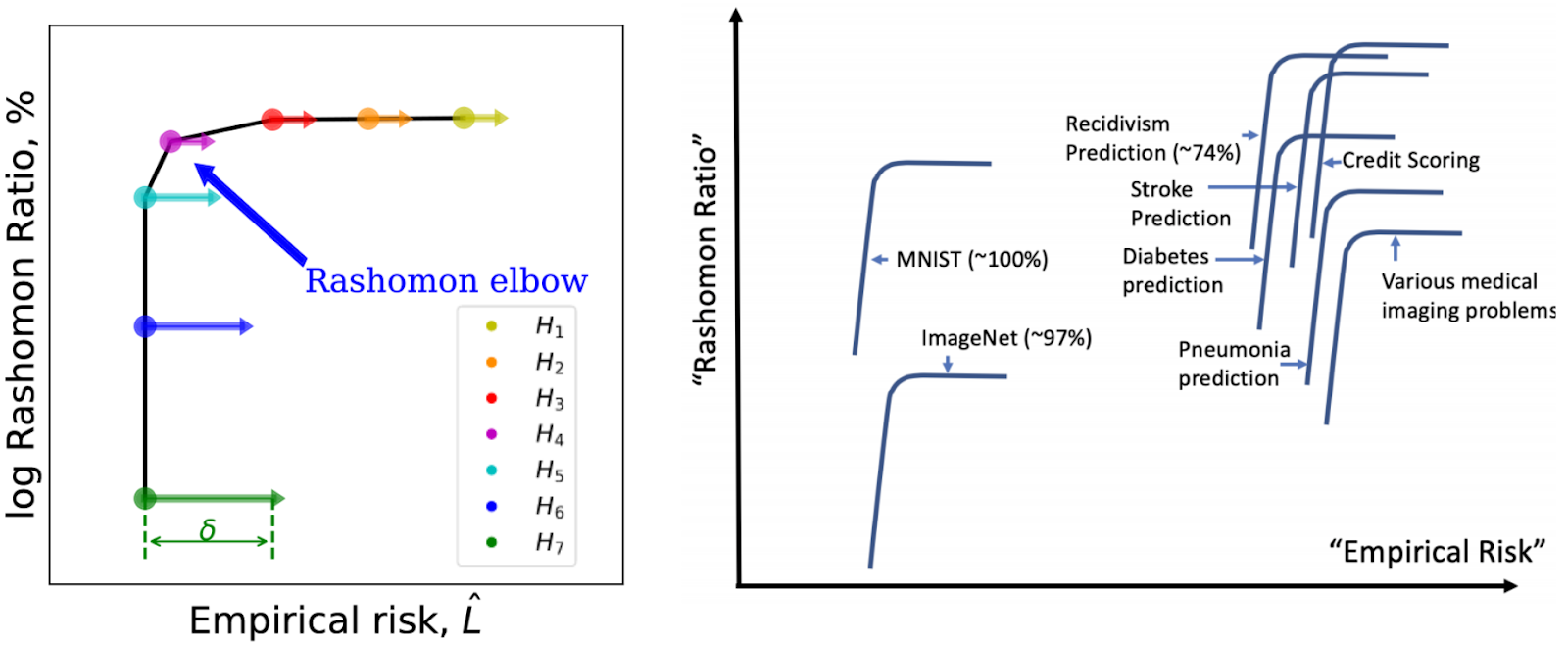
When solving an ML problem, one might consider a hierarchy of model classes starting from simpler to more complex model (hypothesis) classes. In the beginning, the model classes remain too simple for the ML task and the model’s error rate continues to decrease with increasing complexity. This observation corresponds to moving along the horizontal part of the Rashomon curve from right to left. In this case, the Rashomon volume grows at about the same rate as the volume of all the set of all possible models (with varying accuracy). In the regime when the ML model classes start to become too complex for the ML tasks, the model error rates remain the same. This corresponds to traversing the vertical part of the Rashomon curve from the top toward the bottom. In this regime, the set of all possible models outgrow the Rashomon set and the Rashomon ratio drops sharply. The turning point in the Rashomon curve (“Rashomon elbow”) is a sweet spot where lower complexity (higher log Rashomon ratio) and higher accuracy (low empirical risk) meet. Thus, among the hierarchy of model classes, those that fall in the vicinity of the Rashomon elbow are likely to have the right level of complexity for achieving the best balance of high accuracy with desired properties such as generalizability and interpretability.
Local vs. Global Explanation
Interpretability methods can provide two types of explanations: local and global¹⁶. Local explanations describe how a model classifies a single data instance, and answer questions such as, “Which data element(s) are most responsible for the classification output?” In image classification, this is equivalent to identifying which pixel is responsible for a “cat” image class prediction, and by how much. Local explanations are crucial for investigating ML decisions around individual data points.
![LIME [local interpretable model-agnostic explanations taken from [2]]. The original model’s decision function is represented by the blue/pink background, and is clearly nonlinear. The bright red cross is the instance being explained (let’s call it X). Perturbed instances are sampled around X and are weighted according to their proximity to X (weight here is represented by size). Original model predictions are calculated on these perturbed instances. These are used to train a linear model (dashed line) that approximates the model well in the vicinity of X. Note that the explanation in this case is not faithful globally, but it is faithful locally around X.](https://productivityhub.org/wp-content/uploads/2019/10/97576-https3a2f2fmiro.medium.com2fmax2f10882f0i-dacdshkkkfwyqb.png)
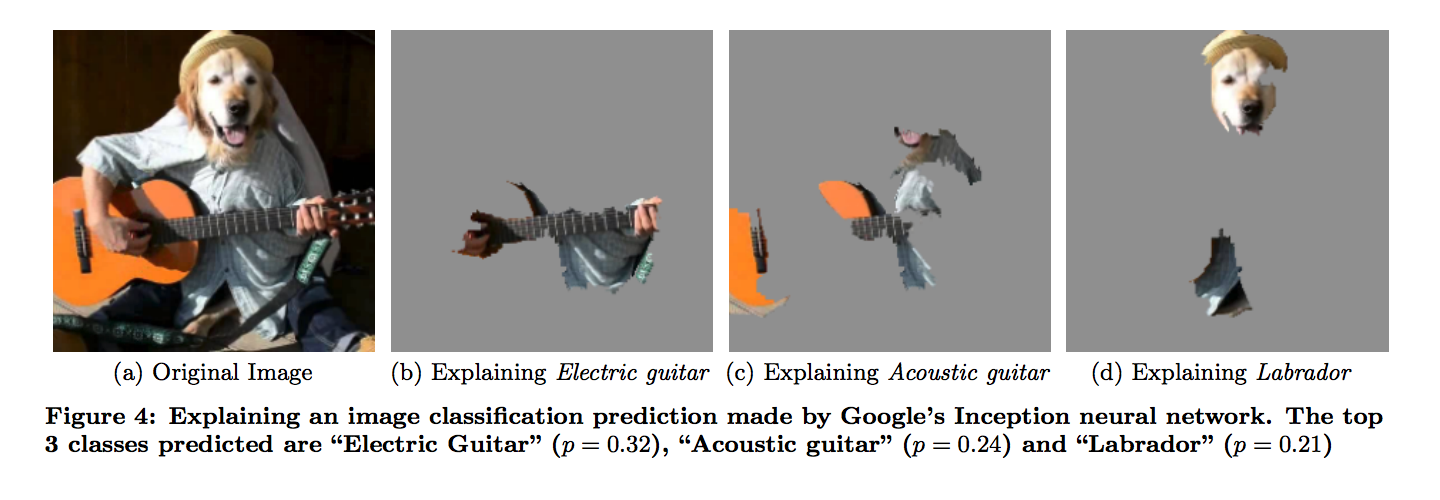
A global explanation, on the other hand, attempts to provide a holistic summarization of how a model generates predictions for an entire class of objects or data sets, rather than focusing on a single prediction and data point.
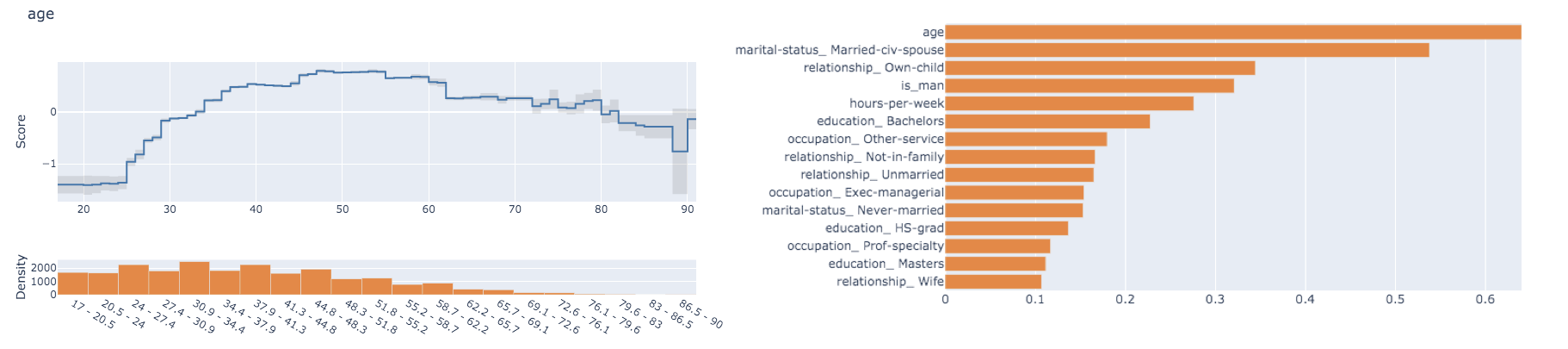
The two most popular techniques for global explanations are feature importance and partial dependence plots. Feature importance provides a score that indicates how useful or valuable each feature was in the construction of the model. In models based on decision trees (like random forests or gradient boosting), the more a feature is used to make key decisions within the decision trees, the higher its relative importance. Partial dependence plots (PDP) show the dependence between the target variable and a set of “target” features, marginalizing over the values of all other features (the “complement” features). Intuitively, we can interpret the partial dependence as the expected target response as a function of the “target” features. A partial dependence plot helps us understand how a specific feature value affects predictions, which can be useful for model and data debugging as demonstrated in¹².
Feature-based vs. concept-based explanation
Early interpretability methods relied on using input features to construct the explanation. This approach is known as feature-based explanation. A key difficulty with feature-based explanations is that most ML models operate on features, such as pixel values, that do not correspond to high-level concepts that humans can easily understand. In her KDD XAI 2019 keynote, Been Kim, Senior Research Scientist at Google Brain, pointed out that feature-based explanations applied to state-of-the-art complex black-box models (such as InceptionV3 or GoogleLeNet) can yield non-sensible explanations¹⁷ ¹⁸. More importantly, feature-based explanations for ML problems where the input features have high dimensionality does not necessarily lead to human-friendly explanations.
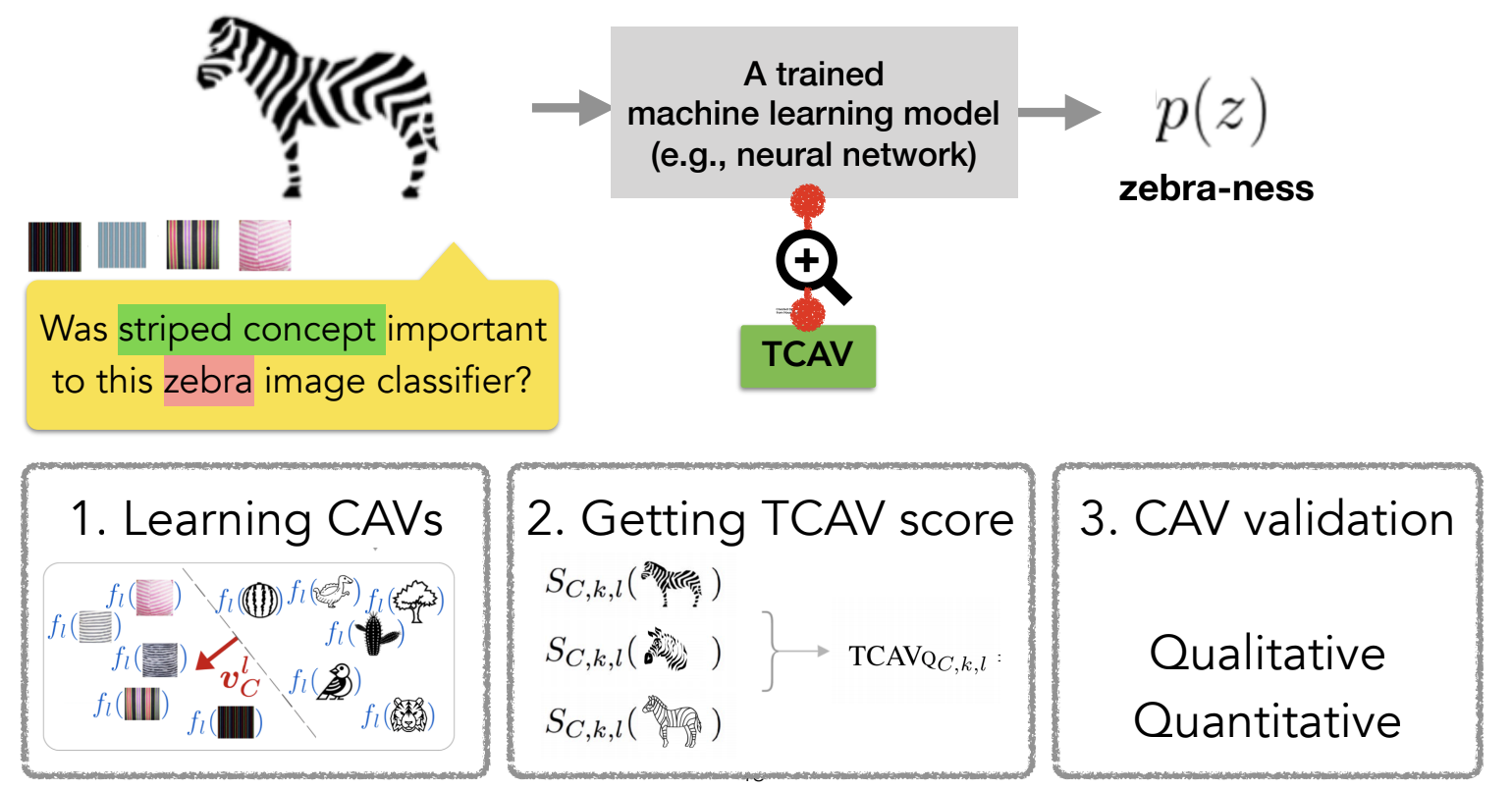
Concept-based explainability constructs the explanation based on human-defined concepts rather than a representation of the inputs based on features and internal model (activation) states. To achieve this, the input feature and model internal state and human-defined concept are represented in two vector spaces: (Em) and (Eh), respectively. The functional mapping between these two vector spaces, if it exists, provides a way of extracting human-defined concepts from input features and ML model internal states.
In her keynote, Kim presented testing with concept activation vector (TCAV), a procedure to quantitatively translate between the human-defined concept space (Eh) and the model internal state (Em)¹⁹. TCAV requires two main ingredients: (1) concept-containing inputs and negative samples (random inputs), and (2) pretrained ML models on which the concepts are tested. To test how well a trained ML model captured a particular concept, the concept-containing and random inputs are inferenced on subcomponents (layers) of a trained ML model. Then, a linear classifier such as a support vector machine is trained to distinguish the activation of the network due to concept-containing vs. random inputs. A result of this training are concept activation vectors (CAVs). Once CAVs are defined, the directional derivative of the class probability along CAVs can be computed for each instance that belong to a class. Finally, the “concept importance” for a class is computed as a fraction of the instances in the class that get positively activated by the concept containing inputs vs. random inputs. This approach allows humans to ask whether a model “learns” a particular expressible concept, and how well.
For example, a human can ask how well a computer vision model “X” learns to associate the concept of “white coat” or “stethoscope” in doctor images using TCAV. To do this, human testers can first assemble a collection of images containing white coats and random images, then apply the pretrained “X” on this collection of images to get the predictions, and compute the TCAV scores for the “white coat” concept. This TCAV score quantifies how important the concept of “white coat” was to a prediction of class “doctor” in an image classification task. TCAV is an example-driven approach, so it still requires careful selection of the concept data instances as inputs. TCAV also relies on humans to generate concepts to test, and on having the concept be expressible in the concept inputs.

Concept-based interpretability methods like TCAV are a step toward extracting “human-friendly” ML explanations. It is up to today’s ML practitioners to make responsible and correct judgment calls on whether model predictions are sensible, and whether they align with our positive values. It is up to us to correct the defects in trained black-box ML models, and TCAV can help illuminate where the flaws are.
What can we do better?
As a community of ML practitioners, it’s our responsibility to clearly define what we want Explainable AI to become, and to establish guidelines for generating explanations that take into consideration what piece of information to use, how (in what manner) to construct the explainability in a way that is beneficial (not harmful or abusive), and when (in which situation/context and to whom) to deliver it. While today’s Explainable AI methods help to pinpoint the defects in ML systems, there’s much work ahead of us.
For now, here are some tips for bringing explainability to the forefront of today’s practice:
- Choose an intelligible model whenever possible.
- Make sure the model and data align with your domain knowledge and societal values, using intelligible models and local explanations.
- Measure machine learning model performance to be sure decisions are aligned with societal values (for example, when modeling data includes protected groups, optimize for consistency and equal opportunity, as well as accuracy)²⁰.
- Build causality into model explanations²¹.
- Measure explanation usefulness and actionability²².
Closing Thoughts
In the span of a few short years, explainable AI as a field has come a very long way. As co-organizers of this workshop, we were privileged to witness tremendous enthusiasm for explainability in ML. For all of us, explainability can be our “true North.” How we can use ML responsibly by ensuring that “our values are aligned and our knowledge is reflected” for the benefit of humanity. This goes beyond achieving end user’ trust or achieving fairness in a narrowly-defined sense. We want to use explainability in conjunction with societal values for the benefit of everyone whose life and livelihood comes into contact with, or is affected by, ML.
Acknowledgment
We would like to thank the community of volunteers who helped review the XAI KDD workshop papers in a timely manner. We are also grateful to our workshop speakers and panelists for sharing their knowledge, wisdom and superb content.
All Rights Reserved for Rich Caruana
