


Who hasn’t heard of Intel, the tech giant setting the pace with its processors? While it used to lead the computing devices industry, its reputation was slowly being eclipsed lately due to competitors sprouting up, with processors for mobile and other next-generation devices. Fortunately, this tech leader does not plan on getting submerged anytime soon. To quote Ingrid Lunden in her TechCrunch article,
The company has set its sights on being at the centre of the next wave of computing, and that is the wider context for its focus on R&D and other investments in AI.
That’s right: Intel used to set the trend in computing, and it plans to do the same for Artificial Intelligence. The latest step in this endeavour: acquire Vertex.AI, as announced on 16th August 2018, and get this team to work alongside Intel’s Movidius team.


Not really clear what this means and how it will impact deep learning, is it? We’ll break it down into segments and understand each one to have a much better view of the whole picture. In so doing, we shall see how this move will affect progress in the field.
The Cloud: There and Back Again
A Machine Learning (ML) or Deep Learning (DL) model needs to be trained, tested and deployed for it to be suitable for use, and this is where the trouble comes in: these require lots of calculations! As better and more complex algorithms were developed, there came a point where laptops could not cope within reasonable timeframes anymore. Who would want to leave their laptop crunching away at mathematical operations for four consecutive days? So developers resorted to having their models running on the cloud, using services such as Google Cloud platform and Amazon Web Services. This way, they had their laptops free for other tasks.


These solutions, while convenient in the sense that developers now had their laptops free, were unfortunately not suitable for problems where speed was crucial, in other words real-time problems (examples mentioned further down). Centralised cloud computing is expected to become cumbersome as more and more people use such services, since the latency during communication is expected to increase. If only developers had some device, like a USB, whose purpose was to do those intensive computations, models could be deployed locally and give almost immediate responses… Enter Intel Movidius!
Intel Movidius
As described in Siraj Raval’s video, the Intel Movidius Neural Compute Stick, created by a team at Intel named Intel Movidius, is a device that brings the model from ‘The Cloud’ (online, in a remote server) to ‘The Edge’ (locally). In other words, it allows the user to test and deploy models locally. Real-time use can now be done faster since no communication with a data server is needed. Additionally, there are fewer issues regarding data privacy since the data is kept local and not sent to the centralised server.
The Intel Movidius Neural Compute Stick *heavy breathing*
Applications are varied, examples including smart security cameras, gesture-controlled drones and industrial machine vision equipment, as stated on Intel’s NCS page. Notice that speed is primordial in these applications. For example, in the gesture-controlled drone scenario, if the drone detects someone throwing an object at it, the best solution would be to dodge as fast as possible by deciding right away instead of recording the scene, sending it to a server, awaiting a reply and then acting based on the reply.
Alright, but how is that connected to Vertex.AI? Well, we’ll find that out!
Vertex.AI, and how their joining Intel will impact Deep Learning
Vertex.AI is a startup with the following purpose stated on their website:
We’re working to bring the power of neural nets to every application, using new technology invented and built in-house, to make applications that weren’t possible, possible.
Vertex.AI is building a platform called PlaidML, whose mission is to enable high-performance neural nets on any device. A very noble mission indeed, as they are already the fastest and easiest platform for enabling compability of such algorithms with operating systems (Linux, Windows, macOS) and hardware (Intel, AMD, ARM, etc…), as mentioned on the project’s Github repository. Hm…fastest and easiest, so how much of a hole is that going to make in the user’s budget? Well, the project being open-source (hence visible to anyone on Github), the platform is free to use!

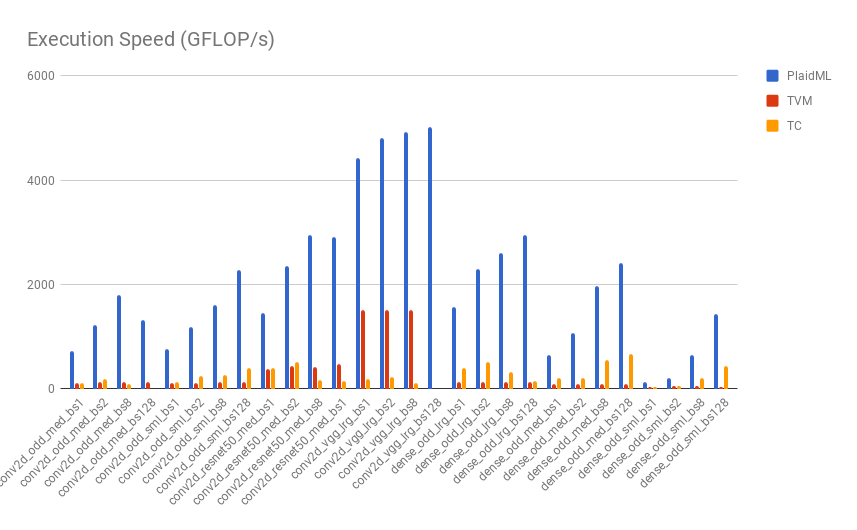
A comparison of PlaidML with alternative tensor compilers (TVM and Tensorflow Comprehension)
Now we have different pieces of the puzzle; all that’s left is to put them together.
- The Intel Movidius team has worked hard and come up with the Intel Movidius Neural Compute Stick, which can perform calculations for models deployed locally. This adds speed and removes the need for communication with a centralised data server.
- Intel has acquired Vertex.AI, whose purpose is, in short, to make Deep Learning work everywhere, and plans to have this team work alongside Intel Movidius.


(Sourced from https://www.cbronline.com/news/startup-vertex-ai)
What can be expected in the next few years (if not months), is a boom in real-time deep learning applications (enabled by Movidius), working on all platforms (enabled by Vertex.AI). This increase will happen as both teams work together to meet their set goals and awareness about this combination rises. The real-time apps will be as varied as our imagination stretches, and shall help propel humanity along the path of progress in Artificial Intelligence.
All Rights Reserved for Hans A. Gunnoo

One Comment