

Taking a deeper look at the most frequently asked Google coding question
If one of your New Years’ goals is to obtain a job at a big tech company and have no experience with answering algorithm questions, you’re in luck. If you aren’t aware of how technical interviews are conducted, you will typically be asked 1–2 algorithm-focused problems in a one-hour window, specifically 45 minutes for Google. Today, we’ll be taking a look at the most frequently asked Google Whiteboarding Question of 2020 utilizing the UMPIRE method, which I explained in a previous post. Let’s get started.

Problem Statement
Given an array of integers, return indices of the two numbers such that they add up to a specific target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
Example:
Given nums = [2, 7, 11, 15], target = 9,
Credits: https://leetcode.com/problems/two-sum/
Understanding the Problem
The problem statement seems to be pretty clear. In layman’s terms, we want to find two elements within our array that add up to the given target; however, we cannot re-use the same element (both indexes need to be unique from each other). In this step of UMPIRE, I would create my own example and think about how I can approach the answer:
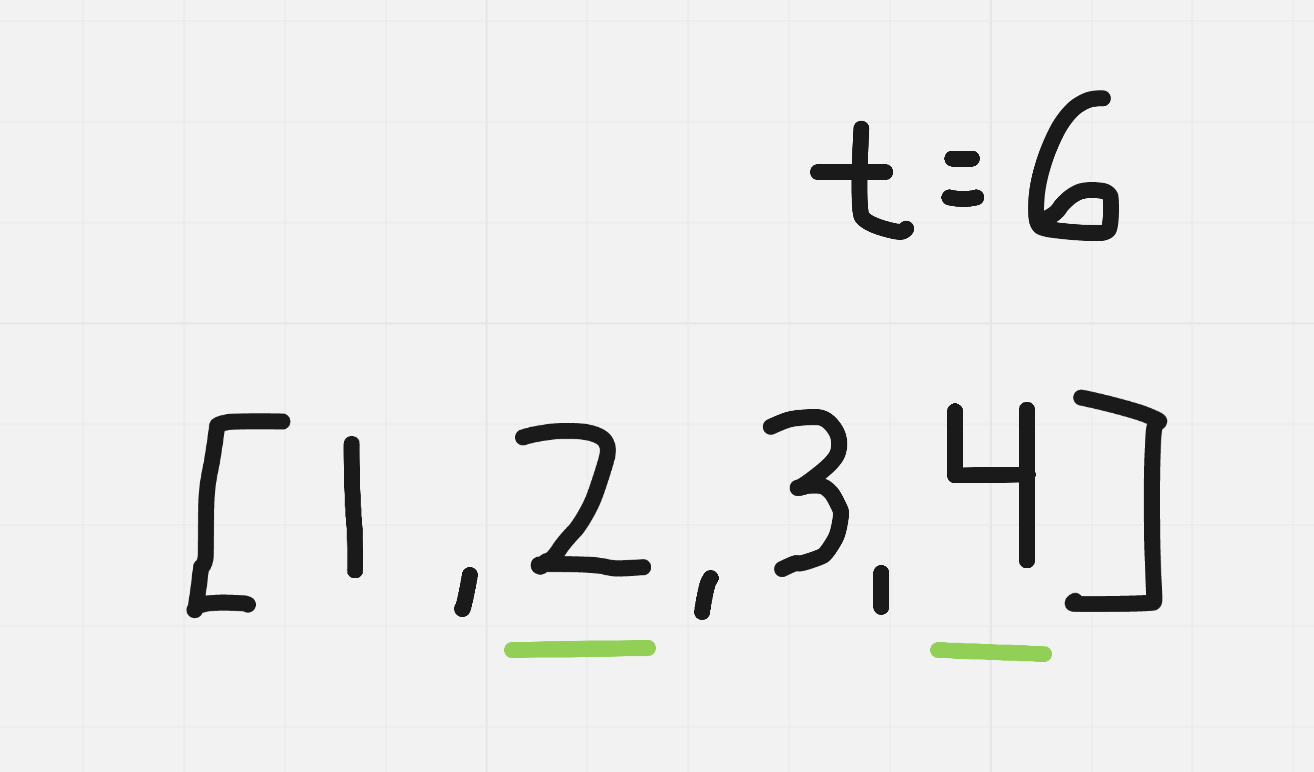
With the example we were given, this example seems to be okay; however, we are making some bold assumptions. We should note that both arrays are in sorted (ascending) order, but assumes the array will always be sorted. We cannot make the assumption that this will always be true. This is a question I would instantly clarify with my interviewer, as it can dramatically change the complexity of our algorithm. In this problem, the interviewer lets us know that we are not guaranteed that the array is in sorted order. Let’s modify our existing example.
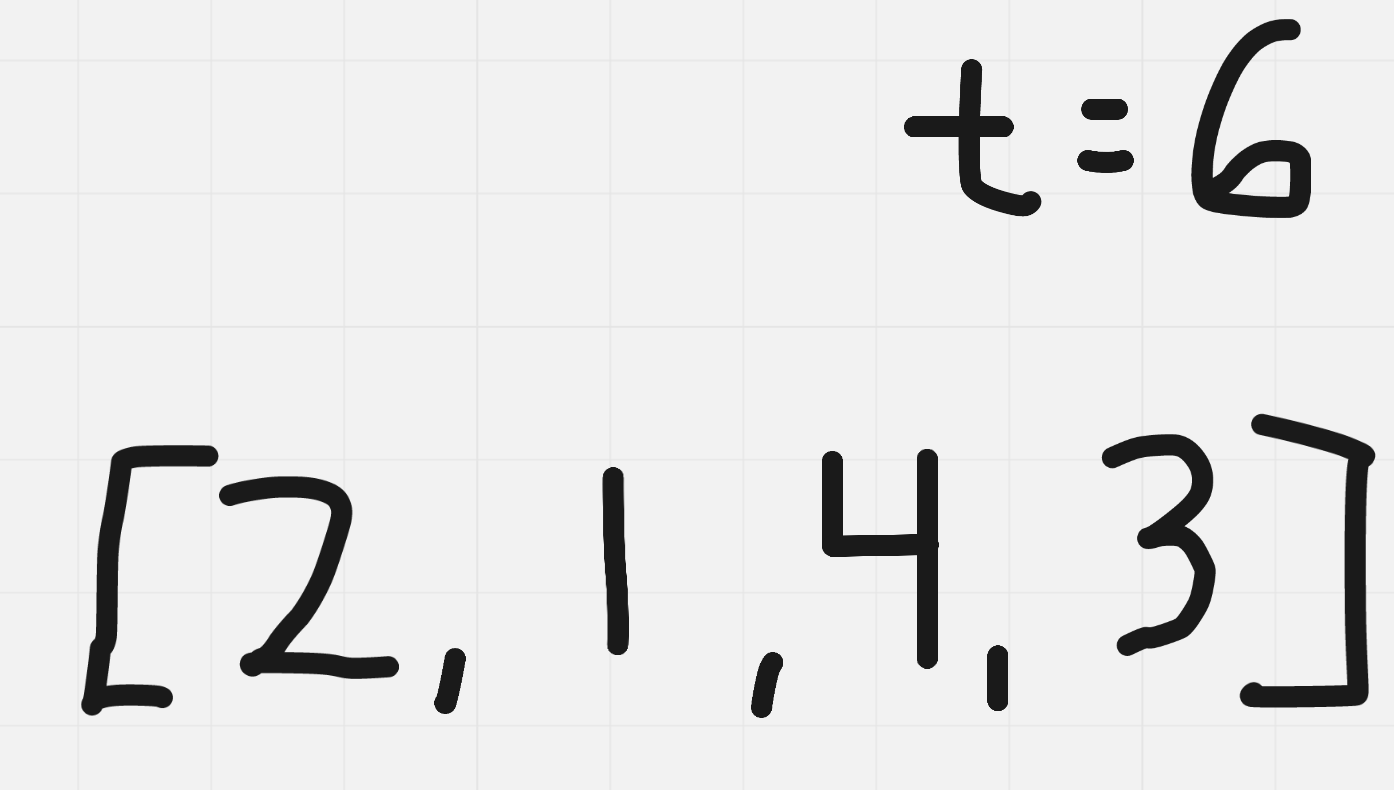
Another property I am taking note of with the given example is that every element in the array is unique. Will this always be true in the arrays I’m given? In other words, is the array [1,1,3,3] a valid input array? We know that we cannot re-use the same index in our return type, but the question does not specify whether or not elements can be repeated. In this case, our interviewer will let us know that all elements will be unique. Cool. Let’s go to the drawing board and figure out some approaches.
The most intuitive approach to me is to take the ith index and check against every other index in my array to check if there exists an element such that, arr[i] + arr[other_index]= target
With this approach, for index 0, it would look something like the following:
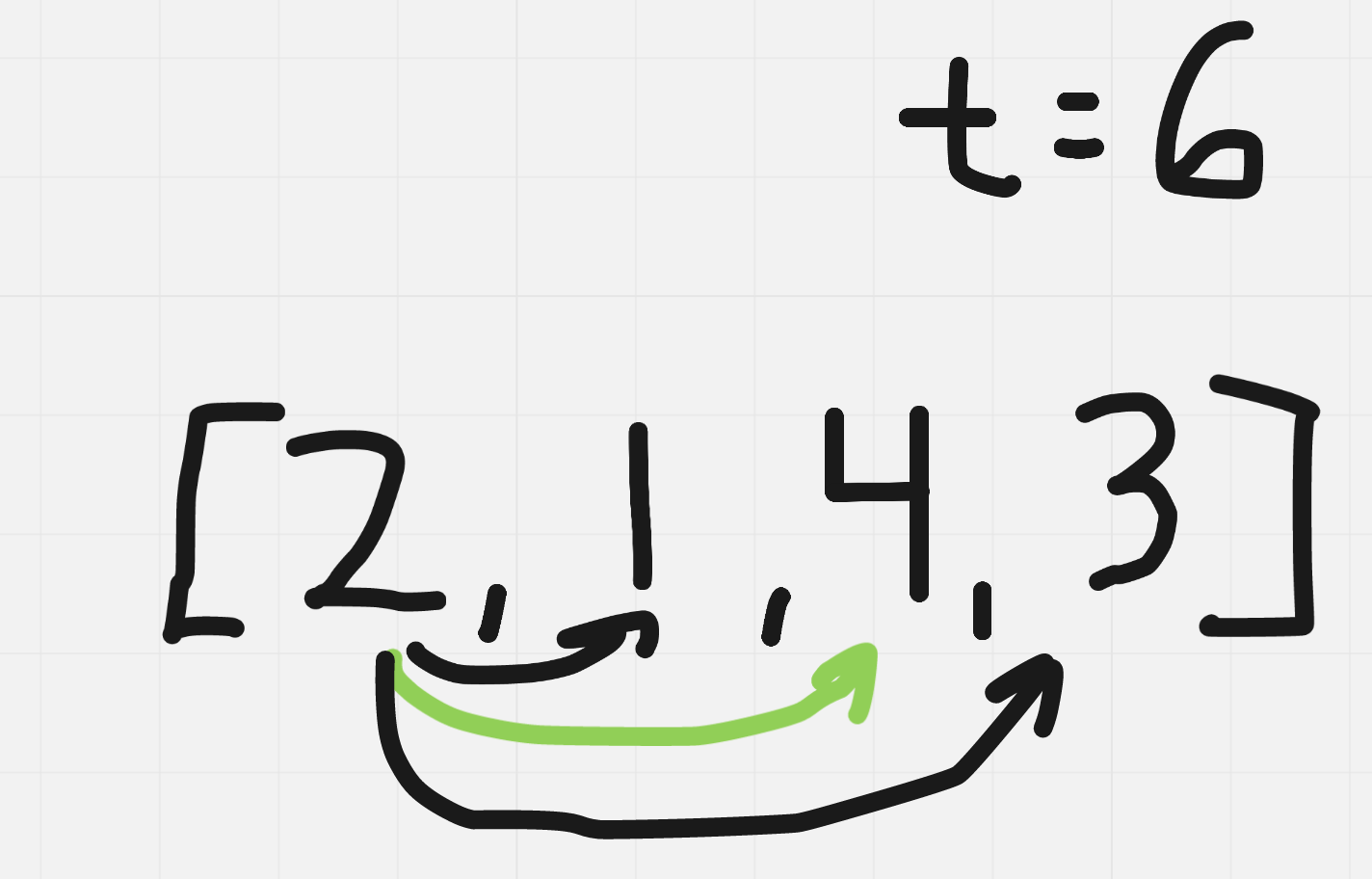
This solution does work. For each index, we are simply checking whether or not there exists that other complement to hit our target. The issue with this, is we have to assume that the array in our algorithm is arbitrarily large. At every index, if we are checking the entire array, we are doing O(N) work at each index.
This will devolve into an algorithm that is running at O(N*N) or O(N²). Let’s think about how we can do better.
Matching the Problem
In our previous approach, we utilized no data structures and our algorithm was running slower than we like — why is that? We were revisiting indexes we already have seen at previous iterations, which means we were doing unneeded computations.
Since the array is unsorted, we have to visit every index of the array at least once in order to know what the contents of our array actually holds. We need to utilize a different data structure that can represent the contents in our array. Ideally, we would like to have a data structure that can tell us quickly whether or not an element exists. To check if an array contains a specific element, we must look through the entire array (since it is sorted) and this slows us down a lot for each iteration. To make the algorithm run faster, my thoughts instantly jump to using a hashtable.
Hashtables are a key-value paired data structure. On the average case, we are able to check if a key exists in constant time. In the problem statement, we want to return the indexes that make up our target, so we can map the value to be the index in which we say the key.
Planning the Solution
This is the time where we want to write out, in plain English, what we want our algorithm to do. This will include necessary helper functions we would want to leverage — make sure you utilize this modular approach of coding to save yourself time on the real task at hand.
The first thing we want to do is populate our hashtable with keys that are the values in the array, and their respective values to be the index in which we saw them.
So in the example we created above, we would expect hashTable to contain:
{
‘1’: 1,
‘2’: 0,
‘3’: 3,
‘4’: 2
}
After we have this initialized, what else do we want to do? All we actually need to do is simply walk through the array once more and check if the complement of our target exists in our hashtable. In other words, does target — arr[i] exist in our hashtable? If it does, great, we found the solution; otherwise, we need to keep walking through the array and keep doing this check.
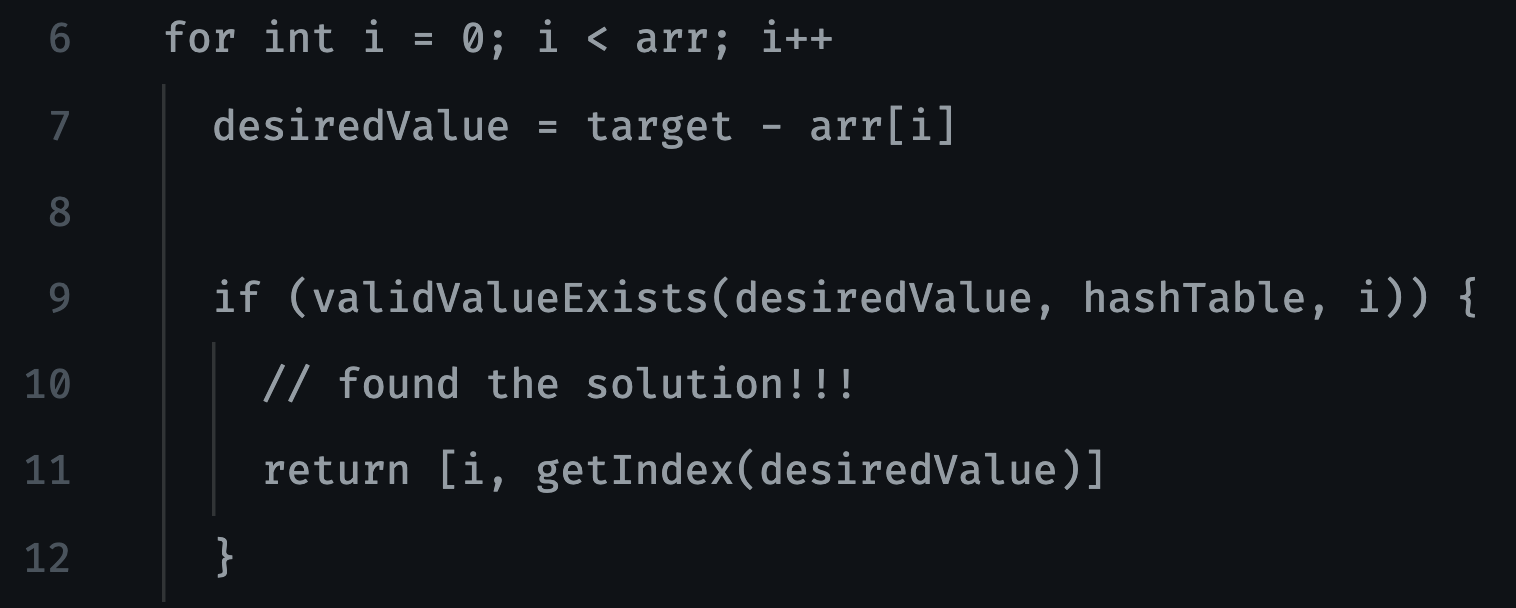
With this step in UMPIRE, you should try to focus on your approach as much as possible, and make what you write as easy to read as possible, so that you can reference it when you start writing your compilable code. We may not want the validValueExists() or getIndex() method, but for the sake of readability, we just want it to be as readable as possible at this point. In my own interviews, I would modularize my code as much as possible. Since we are under a time constraint in our interview, we can always note what each method will do and in the event of running out of time (it happens), the interviewer knew what our intentions were.
Let’s convert this into a compilable code.
Implementing Your Solution
Given the previous steps, this should be the most trivial step, as we already have a blueprint of what exactly we want.
Reviewing Your Solution
At this point in the interview, you want to use the example you created in the previous step and trace through your code, line by line. This will exhibit to your interviewer that you possess strong tracing and logic skills. As an exercise, I suggest you trace through my/your own solution to this problem before running it on your computer. Some companies, such as Google and Facebook, don’t run your code on a computer, so this skill is 100% vital to develop, while other companies such as Uber & Airbnb will also expect your code to compile and run correctly against test cases.
Evaluating Your Solution
While we already evaluated our initial solution’s complexities to recognize that it was inefficient, it does not hurt to reiterate the space and runtime complexity of your solution after implementing your optimal solution. Let’s define N to be the length of our input array. Since we are populating our hashtable with N elements in all cases, we can say that our space complexity is O(N). We are also walking through the array at a minimum one time, so for runtime, we can denote that it is O(N), on the average case. Checking if an element exists within a hashtable, on average, is O(1). In reality, our runtime would be similar to O(N+(N*1)), but this reduces to simply be O(N).
Takeaways
The way you tackle a problem is extremely important. Never, ever, EVER, start a problem off by instantly coding what you think is the solution.
Interview problems can look deceptively easy. It should also be noted that we need to know what data structures we have access to, and how we can leverage them to solve the problem at hand. For example, if we did not know what a hashtable was, we would have had a really difficult time finding a more optimal solution than the naive O(n²) approach.
All Rights Reserved for Joey Colon
