

Explanation of the Existing system and steps required for eye gaze estimation
Introduction :
Eye gaze tracking technology over the past few decades has led to the development of promising gaze estimation techniques and applications for human-computer interaction. Historically, research on gaze tracking dates back to the early 1900s, starting with invasive eye-tracking techniques. These included electro-occulography using pairs of electrodes placed around the eyes or the scleral search methods that include coils embedded into a contact lens adhering to the eyes. This changed in the 1990s as eye gaze found applications in computer input and control. Post-2000, rapid advancements in computing speed, digital video processing, and low-cost hardware brought gaze tracking equipment closer to users, with applications in gaming, virtual reality, and web-advertisements.In the current scenario, eye gaze is used in many aspects of artificial intelligence, machine learning, computer vision, etc.

The eye gaze brings human and machine interaction closer by applying a few approaches and algorithms.
Oh hey ! If you are a beginner, Congratulation ! you are at the right place to gain more knowledge and if not then it could be a cute refresher for you and may remind you of your beginner’s days.
What is an eye tracker :

Well, I know, you’ll say eye tracking was never a piece of cake, guess what ! you are right. Although computer vision has many algorithms for efficient task performance, those algorithms still have some limitations. Eye-tracking can be seen as following the direction of eyes on the computer screen, performing mouse click tasks using eyes i.e. giving commands using eye blinks and it is also possible to identify few emotions using eyes.
“ Eye tracking is the process of measuring either the point of gaze (where one is looking) or the motion of an eye relative to the head. An eye tracker is a device for measuring eye positions and eye movement. ”
Specific activities to perform :

(1) Starting from the formal face and eye detection of the user from a favorable distance.
(2) Detecting the reference points for gaze. ( Reference point: Camera light produces a glint on the cornea of the eye and is called corneal reflection. In most of the existing work, glint has been used as the reference point for gaze estimation. The pupil-glint difference vector remains constant when the eye or the head moves.)
(3) Applying a virtual reference point algorithm for estimation. ( For more details: Virtual reference point )
(4) While performing a project you need to train your algorithm or a script.
(5) Pupil detection and tracking. ( After reading fundamentals you can prefer this article written by Stepan Filonov )
Tracking techniques in action:
(1) The video-based gaze approaches commonly use two types of imaging techniques: infrared imaging and visible imaging. The former needs infrared cameras and infrared light sources to capture the infrared images, while the latter usually utilizes high-resolution cameras for images.
(2) Compared with the infrared-imaging approaches, visible imaging methods circumvent the already known problems without the need for specific infrared devices and infrared light sources. They are not sensitive to the utilization of glasses and infrared sources in the environment. Visible-imaging methods should work in a natural environment, where the ambient light is uncontrolled and usually results in lower contrast images.
(3) Yusuke Sugano has presented an online learning algorithm within the incremental learning framework for gaze estimation, which utilized the user’s operations (i.e., mouse click) on the PC monitor. The first training model was utilized to detect and track the eye and employed the cropped image of the eye to train the Gaussian process functions for gaze estimation. In their applications, a user has to stabilize the position of the head in front of the camera after the training procedure.
(4) Oliver Williams proposed a sparse and semi-supervised A Gaussian process model to infer the gaze, which simplified the process of collecting training data. Generally, it takes a huge amount of data ( images ) from various subjects to train a system for an accurate and efficient result.
Disadvantages of the old system :
I wonder! why these eye gaze algorithms can never be perfect, pretty irritating for computer vision? right. But as the resources are growing, eye gaze is getting algorithms that are more effective, more efficient. peace out! folk. Here are a few disadvantages about old eye gaze system:
(1) The iris center detection will become more difficult than the pupil center detection because the iris is usually partially occluded by the upper eyelid.
(2) The construction of the classifier needs a large number of training samples, which consist of the eye images from subjects looking at different positions on the screen under different conditions.
(3) They are sensitive to head motion and light changes, as well as the number of training samples.
(4) They are not tolerant of head movement.
Steps that require attention :
Identification of face and eye region (R.O.I.):
To start your task, first of all, you’ll need to locate the face and after that, the eyes. In the case of the face, you can see Opencv’s face recognition for basic reference. Eyes are the main priority here and not at all easy to perform the tasks on them. You can see this.


Example of face ROI left and right eyes ROI, and mouth ROI; face ROI was a rectangular shape positioned automatically to cover the face, hair, and neck of models, whilst fixation coordinates within the rectangular areas were assigned to eyes and mouth ROI for each model, respectively. After identifying the area of the face where eyes are located. And then reduces the region specified for more accurate detection of eyes. And then draw small boxes over ROI for more detailed detection.
Finding Pupil Centres:
To estimate gaze direction and position, you must find the pupil center within the bounding box for each eye. For this, you can use a gradient-based method which uses the fact that image gradients at the border of the iris and pupil tend to point directly away from the center of the pupil. It works as follows:
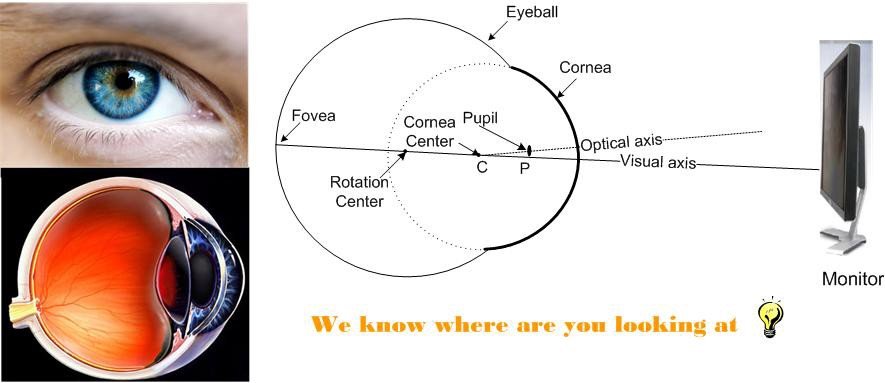
For the below formula, You need to make a unit vector di which points from a given image location to a gradient location, then its squared dot product with the normalized gradient vector gi, expressed as (di T gi) 2, will be maximized if we are at the pupil center. you should do this calculation for each image location and each gradient. The pupil center c* is the location that maximizes the sum of these dot products :
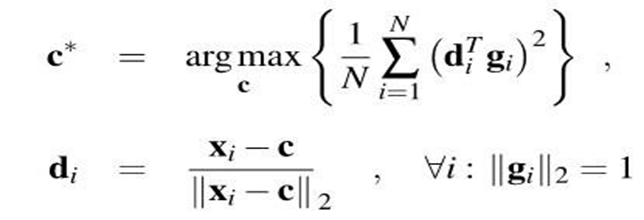
Now proceed with only calculating pupil-center-probability in the dark parts of the image because the pupil is known to be dark. (To do this, perform the threshold on pixel brightness, then dilate the image to expand the allowable areas slightly. You must dilate so that our search region includes parts of the pupil where there are bright reflections.) Eyelashes and shadows produce unwanted gradients, which can produce spurious peaks in the pupil-center probability image. The desired gradients used to be fairly strong, so discard all gradients whose magnitude is below the mean if you want.
This method provides the center of the iris with fairly high reliability, and acceptable accuracy (usually within 3 pixels). However, it can be vulnerable to regions that look similar to a pupil in low-resolution images, such as the shadowed blob on the left of the eye.

Reference Point for Eye Direction :
To detect the pupil coordinates in terms of an offset from some reference point on the face. The Haar Cascade bounding boxes for the face and eyes are not steady enough to serve as reference points, even when averaged together. So you may need to experiment heavily with several other possible reference point methods as draw a blue dot between the eyes with a dry-erase marker and apply the required algorithm to find the center of the blue dot.
Pupil Probability From Two Eyes :
Oh finally, Here comes the probability, something that you are already aware of !. Now first, improve the reliability of your estimation by combining multiple probability estimates. So, you can design a method to combine the estimates from the two eyes: Overlay the probability image from the right eye onto the left eye and multiply the two probabilities.
Eye pupils move together and therefore appear at the same place in the two images. But other (noise-producing) parts of the eye are mirrored about the center-line of the face, and therefore appear at different places in the two images.
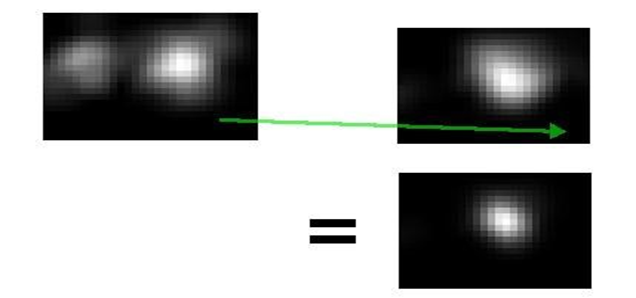
Combining the two eye estimates was not straight forward. Because of the eye bounding boxes are inaccurate, they cannot be used to align the probability images. Insight can be, if the head position is steady, the vector from the left eye’s pupil to the right eye’s pupil is almost constant as the pupils move around. (Especially when the eyes are focused on a plane, such as a computer monitor.) Therefore, if any image region that includes the left eye is shifted by that vector, the left pupil will end up on top of the right pupil.
And hence, time to combine the eye probability estimates without requiring any absolute reference points on the face. (Do one thing: blur both images slightly before the multiplication so that an error of a few pixels in the pupil-pupil vector still yields a strong peak near the true pupil.) The pupil-to-pupil vector can be obtained from the noisy estimates of individual pupil positions. And then simply apply a very slow moving-average filter to reject noise in the estimate of the vector.
Conclusion & possibilities:
The biggest opportunity for improvement is to allow head movement without retraining. (Neither most of the algorithms nor commercial systems can handle head movement.) One possibility for this is to estimate the head position and apply geometry. Side-to-side head movement is detected by the current system and could be used to modify the model in real-time. Distance is not directly sensed by webcams, but the length of our pupil-to-pupil vector could be a very promising signal for estimating distance changes. Head orientation changes would be harder to correct for, as head rotation produces non-linear changes in the reference point’s position relative to the pupils. One option might be to use a Haar cascade to detect the user’s nose and infer head orientation and then apply either machine learning or facial geometry to correct for head orientation’s effect on the reference point.
All Rights Reserved for Hayley Crawford
