

Privacy, as a desire, is universal. Privacy, as a term, is “squishy.”
People across different cultures, living circumstances, and societal structures have an innate instinct to protect private moments. It’s difficult to pin down why — perhaps this elusive quality is why privacy is so difficult to define and regulate. Author and academic Garret Keizer argues we cannot begin to define privacy without recognizing it only exists in the presence of choice. The choice to participate in society, the choice to work, or the choice to share — or not — all play a crucial role in informing our understanding of privacy. Without these choices, we lack agency. Without agency, there can be no privacy.
By most Western measures, privacy is defined as “the right to be let alone.” This definition resulted from a 1965 Supreme Court case in which Justice William O. Douglas acknowledged that while the American Constitution made no explicit provisions for privacy, there are ‘penumbras’ emanating from the Bill of Rights implying ‘zones of privacy’ owed to every citizen.
Penumbra.
You know, the partial shadow lurking just outside the complete shadow of an opaque body such as a planet? That kind of penumbra, duh.
Douglas argued various components of Amendments outlined in the Bill of Rights formed a reasonable ‘zone of privacy’ as a legal construct. Cases decided using ‘penumbral reasoning’ in the ensuing years include the important landmarks Roe v. Wade (1973) and Lawrence v. Texas (2003). While one may personally agree or disagree with these rulings, the right to privacy following from Douglas’s penumbras has inspired little controversy. In fact, it’s incredibly popular with the American public:
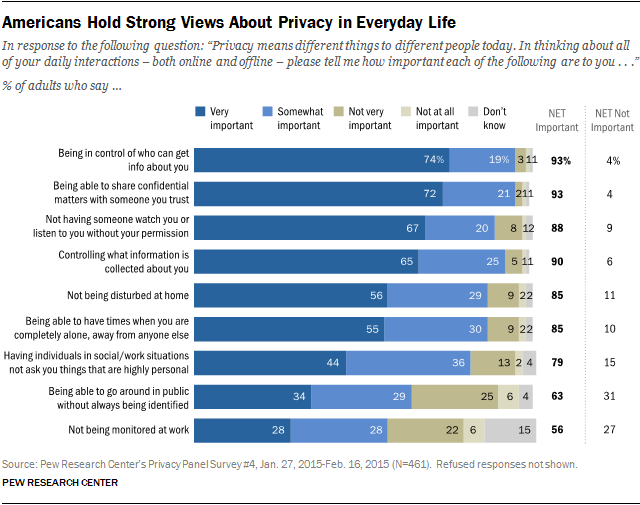
In a 2015 study, Pew Research found 93% of American adults rate control of their own private information and with whom it is shared important. In a world where privacy not only applies to being let alone in the physical domain, but also to the increasingly complex digital one, are ‘penumbras’ really a good enough leg to stand on?
Information privacy.
Information privacy is not as new of a concept as the hype surrounding recent data privacy laws like GDPR or CCPA would have us believe. Structured societies have long had conceptual privacy practices around personal ‘metadata’ such as national government identifiers (Social Security Number in America), financial details, health records, and other sensitive personal information such as sexual orientation or religion. It’s widely agreed that this metadata, or data describing characteristics of its origin (in this case, you!), is vulnerable to abuse in the wrong hands. You can think of all of the different points of classifiable, trackable information about yourself as the ‘metadata of me.’ Some pieces of these data you generate, including those mentioned above, are considered personal data, while the rest may be used to infer other things about you.
Most privacy practices and legislation surrounding these categories of information sprout from discrimination law or concerns over access to personal or tax-based resources. Prior to the rise of Internet-based technologies, the type of information a citizen would generate in a trackable or exploitable manner was pretty predictable and very much tied to physical behaviors like going to the doctor or enrolling in university. Reasonable measures such as select provisions in the Health Insurance Portability and Accountability Act (HIPAA) and the Family Educational Rights and Privacy Act (FERPA) were put in place to protect this data. Many of these laws dealt more with privacy’s oft-conflated sibling, security, than they did with information privacy restrictions.
Wait, what about Security?
Security and privacy are tightly related, but not quite identical, concepts. Security, for starters, has its roots in physical wellbeing. The right to freedom from search and seizure is outlined in the Fourth Amendment to the Constitution. In common security practices and legislation the right is extended to reflect how we prevent harm to ourselves or business entities based on access to information.
The way I describe the difference between privacy and security to curious colleagues is:
Security is about protecting ourselves — Privacy is about respecting ourselves.
Security is concerned with guarding the castle from intruders or mutinous subjects, whereas privacy requires us to check the habits and decision-making of the Lords within. Just because you or your workplace have put security measures in place to protect employee, proprietary, or consumer information you collect from malicious attempts to steal it does not mean that information cannot still be misused by those permitted to access it. Security generally deals with the practical details on location of information, how it is protected, and who has access to it. This is why the Information Security field has so many more widely agreed upon frameworks for data protection globally — it doesn’t live in the penumbras.
Yes, whereas security has its foundations in the physical (or at least tangible digital infrastructure), the pesky penumbras inspire questions around interpretations and applications of ‘standard’ privacy practices. As information privacy extends to the ever-increasing pile of metadata we generate on a day-to-day basis just by walking around with our phones in our pockets, new technical and regulatory frameworks have emerged to address misuse.
Data Privacy & the right to be let alone.
Information privacy and data privacy are often loosely interchangeable, but one could argue our 2020 notion of data privacy followed from information privacy concepts as a result of tremendous technological change. Our media outlets and legislative bodies almost exclusively focus on data privacy as it relates to the digital world, and very little of a person’s metadata is not online today.
Data privacy is largely concerned with the right of a person, or, as you are described in the legislation, a “data subject,” to dictate which metadata about them can be collected and to whom it can be distributed. The data privacy field hopes to ensure that data subjects are provided with a clear opportunity to exercise choice over use of their data and that these choices are respected.
This probably reminds you of all of the privacy policies, terms & conditions, and ‘unsubscribes’ you are exposed to on a regular basis. Some of you may even be starting to see more widespread use of cookie notices online or on your mobile apps — that’s a good sign that the services you use are at least attempting to respect new data privacy laws. The buttons you press will dictate how another party uses the metadata you generate or provide on the service, so choose wisely!
While you may get annoyed by the constant banners and nudges to accept or reject terms & conditions, those little buttons represent your right to be let alone. It’s somewhat easy to see how the right to be let alone was exercised in the pre-Internet era — if I wanted some time to myself or not to disclose my information, I simply went to another room or didn’t share it. Now, it’s not so clear. Reliance on digital services for learning and participation in society mean we are more and more willing to sacrifice ‘aloneness.’ So what does that mean for the right to privacy?
While it’s true that our personal devices, tracking & surveillance technologies, and the Internet of Things render us rarely alone, we are in the midst of a reckoning with whether we should forgo privacy just because technology can. Emerging regulatory data privacy frameworks, and the legislators, privacy professionals, and privacy-conscious technologists behind them, attempt to protect our choice to withhold our data and still get utility from technological innovation — our right to still be let alone.
All Rights Reserved for Lauren Kaufman
