
The machine learning outfit’s foray into pharmaceuticals could be very useful, but its grand claims should be taken with a pinch of salt
The most interesting development of the week had nothing to do with Facebook or even Google losing its appeal against a €2.4bn fine from the European commission for abusing its monopoly of search to the detriment of competitors to its shopping service. The bigger deal was that DeepMind, a London-based offshoot of Google (or, to be precise, its holding company, Alphabet) was moving into the pharmaceutical business via a new company called Isomorphic Labs, the goal of which is grandly described as “reimagining the entire drug discovery process from first principles with an AI-first approach”.
Since they’re interested in first principles, let us first clarify that reference to AI. What it means in this context is not anything that is artificially intelligent, but simply machine learning, a technology of which DeepMind is an acknowledged master. AI has become a classic example of Orwellian newspeak adopted by the tech industry to sanitise a data-gobbling, energy-intensive technology that, like most things digital, has both socially useful and dystopian applications.
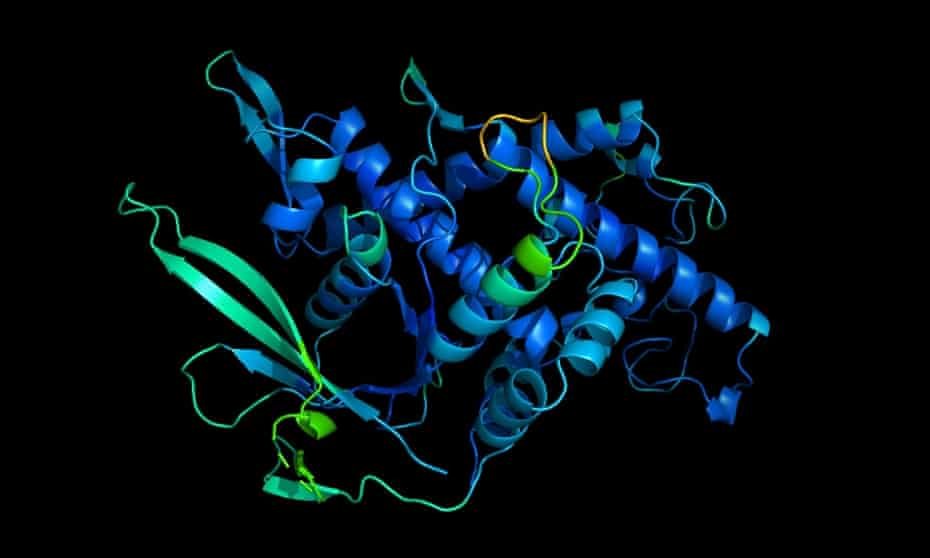
That said, this new venture by DeepMind seems more on the socially useful side of the equation. This is because its researchers have discovered that its technology might play an important role in solving a central problem in biology, that of protein folding.
Proteins are large, complex molecules that do most of the heavy lifting in living organisms. Almost every bodily function – contracting muscles, sensing light, digesting food, running the immune system, you name it – relies on proteins. And what a given protein can do depends on its three-dimensional structure.
The problem is that although we can now read the genetic sequence for a protein, that doesn’t tell us how it will fold into the 3D shape that determines its function. And predicting structure from the sequence is a very hard problem indeed. Way back in 1969, the American molecular biologist Cyrus Levinthal estimated that the number of possible foldings of a fairly typical protein could be 10 to the power of 300, which, if one were to go through each of the possibilities, would take longer than the current age of the universe to unravel!
Every two years, the research community focused on the folding problem holds a competition for computational prediction of protein structure. In 2018, DeepMind’s Alphafold machine-learning software entered the fray and – unexpectedly – came out ahead of other teams. Last November, even the normally sober Nature described it as coming “head and shoulders” above the 100 research teams participating in the 2020 competition.
So it easy to see why DeepMind thought it was on to something. On the one hand, being able to determine protein structure quickly could be a real boon for medical diagnosis and care. (Protein misfolding is believed to play an important role in Parkinson’s disease, for example.) On the other hand, vast though the tech industry is, healthcare is a lot bigger and if Alphabet is thinking about what to do now that it has solved search, then Isomorphic Labs might turn out to be a shrewd investment. (It might also ease the misgivings of some DeepMind geeksabout working for a surveillance capitalism empire.)
AI has become a classic example of Orwellian newspeak adopted by the tech industry
For machine-learning evangelists, DeepMind’s latest foray into molecular biology will be hailed as further evidence that conventional ways of doing science – formulating hypotheses, devising ways of testing them, collecting data or doing experiments, peer review, etc – are obsolescent. If that’s what some enthusiasts think, then they haven’t understood either machine learning or science. What DeepMind has brilliantly demonstrated is that the combination of smart algorithms and brute-force computing is good at some rather specialised tasks, such as games, where there are known rules and clear criteria for success. Or, more to the point, predicting protein structures. Whether the combination is as effective in less structured domains remains to be seen.
That doesn’t mean that the technology isn’t useful in lots of scientific domains. What it’s particularly good at is extracting patterns from colossal troves of data, which is why, for example, astrophysicists and particle physicists love it. This is why many observers see it as a useful tool for discovery. Machine learning provides a way of finding correlations – sometimes strange and unexpected ones – in mountains of data, as, for example, when Walmart discovered that American customers stocking up before hurricane warnings tended to buy pop tarts as well as the usual precautionary supplies.
Correlations like that might be useful to a supermarket retailer, but correlation, as every GCSE maths student knows, is not the same thing as causation. Divorce rates in Maine are closely correlated with per capita consumption of margarine in that delightful state. Likewise, the number of people drowned by falling into swimming pools closely tracks the number of films in which the actor Nicolas Cage has appeared. Correlations such as these may be amusing or striking but they contribute nothing to our understanding. For that we need to know how an effect is caused by something else. We need ye olde scientific method, not a fancy neural network.
All Rights Reserved for John Naughton
