


Does the advent of machine learning mean the classic methodology of hypothesise, predict and test has had its day?
Isaac Newton apocryphally discovered his second law – the one about gravity – after an apple fell on his head. Much experimentation and data analysis later, he realised there was a fundamental relationship between force, mass and acceleration. He formulated a theory to describe that relationship – one that could be expressed as an equation, F=ma – and used it to predict the behaviour of objects other than apples. His predictions turned out to be right (if not always precise enough for those who came later).
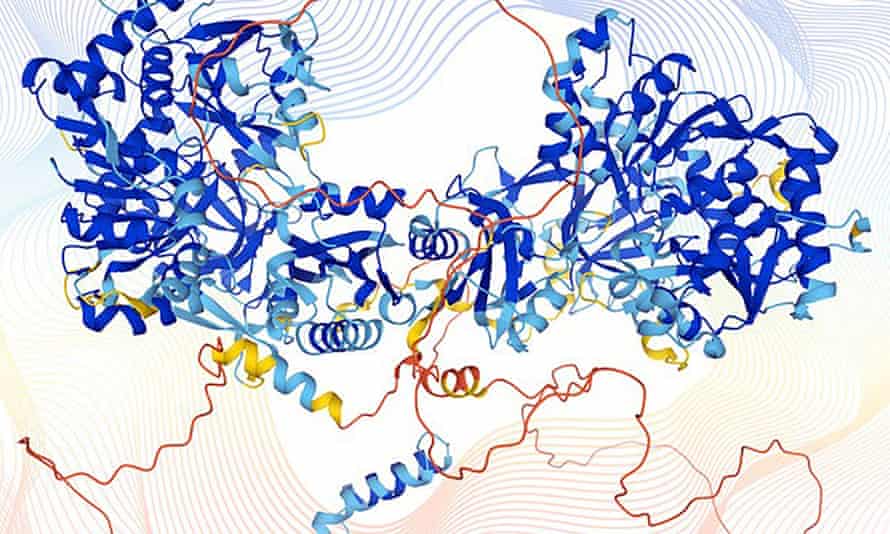
Contrast how science is increasingly done today. Facebook’s machine learningtools predict your preferences better than any psychologist. AlphaFold, a program built by DeepMind, has produced the most accurate predictions yet of protein structures based on the amino acids they contain. Both are completely silent on why they work: why you prefer this or that information; why this sequence generates that structure.
Humans turn out to be deeply uncomfortable with theory-free science
You can’t lift a curtain and peer into the mechanism. They offer up no explanation, no set of rules for converting this into that – no theory, in a word. They just work and do so well. We witness the social effects of Facebook’s predictions daily. AlphaFold has yet to make its impact felt, but many are convinced it will change medicine.
Somewhere between Newton and Mark Zuckerberg, theory took a back seat. In 2008, Chris Anderson, the then editor-in-chief of Wired magazine, predicted its demise. So much data had accumulated, he argued, and computers were already so much better than us at finding relationships within it, that our theories were being exposed for what they were – oversimplifications of reality. Soon, the old scientific method – hypothesise, predict, test – would be relegated to the dustbin of history. We’d stop looking for the causes of things and be satisfied with correlations.

With the benefit of hindsight, we can say that what Anderson saw is true (he wasn’t alone). The complexity that this wealth of data has revealed to us cannot be captured by theory as traditionally understood. “We have leapfrogged over our ability to even write the theories that are going to be useful for description,” says computational neuroscientist Peter Dayan, director of the Max Planck Institute for Biological Cybernetics in Tübingen, Germany. “We don’t even know what they would look like.”
But Anderson’s prediction of the end of theory looks to have been premature – or maybe his thesis was itself an oversimplification. There are several reasons why theory refuses to die, despite the successes of such theory-free prediction engines as Facebook and AlphaFold. All are illuminating, because they force us to ask: what’s the best way to acquire knowledge and where does science go from here?
The first reason is that we’ve realised that artificial intelligences (AIs), particularly a form of machine learning called neural networks, which learn from data without having to be fed explicit instructions, are themselves fallible. Think of the prejudice that has been documented in Google’s search engines and Amazon’shiring tools.
The second is that humans turn out to be deeply uncomfortable with theory-free science. We don’t like dealing with a black box – we want to know why.
And third, there may still be plenty of theory of the traditional kind – that is, graspable by humans – that usefully explains much but has yet to be uncovered.
So theory isn’t dead, yet, but it is changing – perhaps beyond recognition. “The theories that make sense when you have huge amounts of data look quite different from those that make sense when you have small amounts,” says Tom Griffiths, a psychologist at Princeton University.
Griffiths has been using neural nets to help him improve on existing theories in his domain, which is human decision-making. A popular theory of how people make decisions when economic risk is involved is prospect theory, which was formulated by behavioural economists Daniel Kahneman and Amos Tversky in the 1970s (it later won Kahneman a Nobel prize). The idea at its core is that people are sometimes, but not always, rational.

In Science last June, Griffiths’s group described how they trained a neural net on a vast dataset of decisions people took in 10,000 risky choice scenarios, then compared how accurately it predicted further decisions with respect to prospect theory. They found that prospect theory did pretty well, but the neural net showed its worth in highlighting where the theory broke down, that is, where its predictions failed.
These counter-examples were highly informative, Griffiths says, because they revealed more of the complexity that exists in real life. For example, humans are constantly weighing up probabilities based on incoming information, as prospect theory describes. But when there are too many competing probabilities for the brain to compute, they might switch to a different strategy – being guided by a rule of thumb, say – and a stockbroker’s rule of thumb might not be the same as that of a teenage bitcoin trader, since it is drawn from different experiences.
“We’re basically using the machine learning system to identify those cases where we’re seeing something that’s inconsistent with our theory,” Griffiths says. The bigger the dataset, the more inconsistencies the AI learns. The end result is not a theory in the traditional sense of a precise claim about how people make decisions, but a set of claims that is subject to certain constraints. A way to picture it might be as a branching tree of “if… then”-type rules, which is difficult to describe mathematically, let alone in words.
‘AlphaFold will only improve our understanding of life and therapeutics’
What the Princeton psychologists are discovering is still just about explainable, by extension from existing theories. But as they reveal more and more complexity, it will become less so – the logical culmination of that process being the theory-free predictive engines embodied by Facebook or AlphaFold.
Some scientists are comfortable with that, even eager for it. When voice recognition software pioneer Frederick Jelinek said: “Every time I fire a linguist, the performance of the speech recogniser goes up,” he meant that theory was holding back progress – and that was in the 1980s.
Or take protein structures. A protein’s function is largely determined by its structure, so if you want to design a drug that blocks or enhances a given protein’s action, you need to know its structure. AlphaFold was trained on structures that were derived experimentally, using techniques such as X-ray crystallography and at the moment its predictions are considered more reliable for proteins where there is some experimental data available than for those where there is none. But its reliability is improving all the time, says Janet Thornton, former director of the EMBL European Bioinformatics Institute (EMBL-EBI) near Cambridge, and it isn’t the lack of a theory that will stop drug designers using it. “What AlphaFold does is also discovery,” she says, “and it will only improve our understanding of life and therapeutics.”
Others are distinctly less comfortable with where science is heading. Critics point out, for example, that neural nets can throw up spurious correlations, especially if the datasets they are trained on are small. And all datasets are biased, because scientists don’t collect data evenly or neutrally, but always with certain hypotheses or assumptions in mind, assumptions that worked their way damagingly into Google’s and Amazon’s AIs. As philosopher of science Sabina Leonelli of the University of Exeter explains: “The data landscape we’re using is incredibly skewed.”
But while these problems certainly exist, Dayan doesn’t think they’re insurmountable. He points out that humans are biased too and, unlike AIs, “in ways that are very hard to interrogate or correct”. Ultimately, if a theory produces less reliable predictions than an AI, it will be hard to argue that the machine is the more biased of the two.
A tougher obstacle to the new science may be our human need to explain the world – to talk in terms of cause and effect. In 2019, neuroscientists Bingni Brunton and Michael Beyeler of the University of Washington, Seattle, wrote that this need for interpretability may have prevented scientists from making novel insights about the brain, of the kind that only emerges from large datasets. But they also sympathised. If those insights are to be translated into useful things such as drugs and devices, they wrote, “it is imperative that computational models yield insights that are explainable to, and trusted by, clinicians, end-users and industry”.
“Explainable AI”, which addresses how to bridge the interpretability gap, has become a hot topic. But that gap is only set to widen and we might instead be faced with a trade-off: how much predictability are we willing to give up for interpretability?
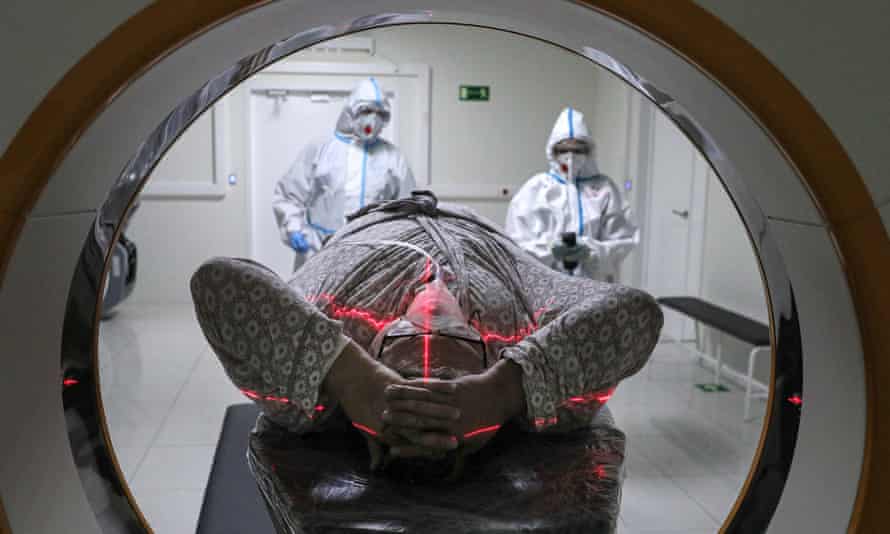
Sumit Chopra, an AI scientist who thinks about the application of machine learning to healthcare at New York University, gives the example of an MRI image. It takes a lot of raw data – and hence scanning time – to produce such an image, which isn’t necessarily the best use of that data if your goal is to accurately detect, say, cancer. You could train an AI to identify what smaller portion of the raw data is sufficient to produce an accurate diagnosis, as validated by other methods, and indeed Chopra’s group has done so. But radiologists and patients remain wedded to the image. “We humans are more comfortable with a 2D image that our eyes can interpret,” he says.
The final objection to post-theory science is that there is likely to be useful old-style theory – that is, generalisations extracted from discrete examples – that remains to be discovered and only humans can do that because it requires intuition. In other words, it requires a kind of instinctive homing in on those properties of the examples that are relevant to the general rule. One reason we consider Newton brilliant is that in order to come up with his second law he had to ignore some data. He had to imagine, for example, that things were falling in a vacuum, free of the interfering effects of air resistance.
In Nature last month, mathematician Christian Stump, of Ruhr University Bochum in Germany, called this intuitive step “the core of the creative process”. But the reason he was writing about it was to say that for the first time, an AI had pulled it off. DeepMind had built a machine-learning program that had prompted mathematicians towards new insights – new generalisations – in the mathematics of knots.
In 2022, therefore, there is almost no stage of the scientific process where AI hasn’t left its footprint. And the more we draw it into our quest for knowledge, the more it changes that quest. We’ll have to learn to live with that, but we can reassure ourselves about one thing: we’re still asking the questions. As Pablo Picasso put it in the 1960s, “computers are useless. They can only give you answers.”
All Rights Reserved for Laura Spinney
