

Understand how Object Detection is applied and implemented using Machine and Deep Learning techniques
Computer vision is a field encapsulated within the broader spectrum of Artificial Intelligence studies. Computer vision involves working with digital images and videos to deduce some understanding of contents within these images and videos.
Object detection is associated with Computer Vision and describes a system that can identify the presence and location of a desired object or body within an image. Do note that there can be singular or multiple occurrences of the object to be detected.
The output of an object detection process is an image with bounding boxes around the objects of interest and an indication as to the class instance of a single object — see the image above.
This article will explore Object Detection and some of the various approaches to implementing object detection using Machine and Deep learning techniques.
Applications
One of the most apparent use cases for Object Detection is within self-driving cars.
Autonomous vehicles have an embedded system that can perform multi-class object detection in real-time and then perform actions based on the detection results.
For example, an autonomous vehicle’s system can detect a human-shaped body crossing the road and proceed to engage a program that causes the car to stop several feet before coming in contact with the detected body.

Other applications of Object Detection are:
- Face Detection: A term given to the task of implementing systems that can automatically recognize and localize human faces in images and videos. Face detection is present in applications associated with facial recognition, photography, and motion capture.
- Pose Estimation: The process of deducing the location of the main joints of a body from provided digital assets such as images, videos, or a sequence of images. Forms of pose estimation are present in applications such as Action recognition, Human interactions, creation of assets for virtual reality and 3D graphics games, robotics and more
- Object Recognition: The process of identifying the class a target object is associated with. Object recognition and detection are techniques with similar end results and implementation approaches. Although the recognition process comes before the detection steps in various systems and algorithms.
- Tracking: A method of identifying, detecting, and following an object of interest within a sequence of images over some time. Applications of tracking within systems are found in many surveillance cameras and traffic monitoring devices.

Machine Learning Approaches
There are machine learning techniques that are used to detect an object within images, and these techniques are manually implemented algorithms, hence they are not learned systems.
Methods such as Histograms of Oriented Gradients(HOG) introduced around 2005 used a combination HOG/SIFT(Scale Invariant Feature transformation) to identify interest points within images based on normalized local histograms of image gradients.
The method is based on the intuition that an object of interest has a distinct set of characteristics that can be identified by the local intensity of gradients and edge direction on a per-window basis. The result is to generate a HOG descriptor that is affine invariant and used in a detection chain that introduces an SVM(Support vector machine) to detect objects of interest-based on the HOG descriptors. This technique works relatively well for general detection scenarios, such as pedestrian detection.
Generating a HOG feature that is affine invariant means that the features used in the descriptors will always present the same descriptors if the features have been moved, scaled or rotated
Below are quick overviews of more Machine Learning techniques for Object Detection:
Scale Invariant Feature Transform (SIFT)
Target objects for detection need to have a unique method to enable identification across images; this novel method is analogous to obtaining a fingerprint of objects in an image.
SIFT is a computer-vision algorithm that identifies and encapsulates the information on local points of interest(features) within an image to describe the objects within the image bases on the extracted features.
For the SIFT algorithm to create an adequate description of the object within an image, the point of interest gathered needs to be able to enable detection when there are inconsistencies in an image such as noise, variation in scale, and orientation. An example of areas of an image that meet the requirements mentions for an adequate descriptor is edge information within the image.

Object Detection based on Haar features
Haar-like features are identifiers within an object that can be utilized for object recognition and detection.
Characteristics of a section of an image can be captured by placing comparing the pixel intensities of two neighboring rectangular regions and finding the difference between the summation. The result of the difference is essentially our descriptor for that particular section of the image.
In a practical scenario, haar-like features can be used within face detection. There are variances of pixel intensities across the human face, for example, the eyes. The eye region has a darker shade in comparison to neighboring areas.

Deep Learning Approach
When utilizing Deep Learning techniques, there are two main approaches to Object Detection, the first being designing and training a network architecture from scratch, including the structure of layers and the initialization of weight parameter values. The second approach is to utilize the concept of Transfer Learningand leverage a pre-trained network that’s trained on a large dataset before the onset of your dedicated training on the custom datasets.
Transfer Learning is the method of reusing knowledge gained from solving a problem and applying the knowledge gained to an associated but separate problem
The second approach eliminates the lengthy time disadvantages accompanied by the first-mentioned approach, which is that the time taken to train a network from scratch is far more significant and will require more effort when compared to adopting an already-trained network.
Below are some quick overview of Convolutional Neural Networks(CNN) models for Object Detection
Region-Based Convolutional Neural Networks (RCNN) And Its Variants
RCNN is a deep learning method for solving object detection and segmentation. The technique was introduced in 2014 and presented the concept of region-based convolutional neural networks or RCNN for short.
RCNN utilizes a selective search algorithm to propose region of interest in an image and, after that, uses a convolutional neural network to detect the presence of the object of interest within the proposed region.
RCNN utilizes CNN for feature extraction and binary SVM for classification of objects. Although RCNNs does consist of a manual technique to propose region of interest, therefore it isn’t truly an end to end learnable solution.
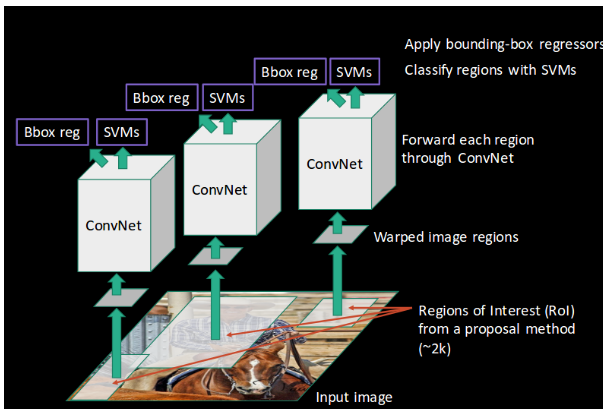
RCNN can be computationally expensive and takes an average of 40–50 seconds to complete predictions on each image. Its successors, Fast-RCNN and Faster-RCNN, tackle some of the performance and efficiency problems prevalent in RCNN. Also, RCNN cannot be used for real-time applications due to the time it takes to conduct and complete predictions on images.
You Only Look Once (YOLO)
YOLO is a redefinition of the standard object detection paradigm utilized by alternative object detection techniques. Popular techniques such as RCNN leverage region-based classifiers and are passing images thousands of times through the network to gain a prediction. Also, RCNN is a two-stage process, the first stage generates the regions of the proposal, and the second stage is where the object detection occurs.
On the other hand, YOLO is a one-step process for object detection. It is also a neural network model that requires just one pass of an image through its network to conduct object detection. An obvious benefit is that YOLO proposes greater efficiency when compared to RCNNs.
YOLO works by overlaying grids on an image, where each cell within the grid plays two roles:
- Each cell predicts bounding boxes, and a confidence value is assigned to each bounding box. The confidence value is a representation of the probability that the content of the grid contains an object. Therefore, the low confidence value is assigned to areas of the image without any objects.
- Each cell also produces a classification probability result. The classification probability represents the chance that if a grid contains an object, the object is likely to be the class with the highest probability.
Using YOLO for object detection has several benefits, the major one being that it can be used within real-time applications such as the object detection systems embedded in autonomous vehicle systems.
Below is a video containing more information on YOLO:
Conclusion
To conclude, we look at the progression and success of object detection techniques, both machine learning, and deep learning approaches.
The image below depicts visually the increase in mAP score (Jonathan Huiexplains mAP scores) of object detection techniques over ten years from 2006–2016 when evaluated on the Pascal VOC dataset.
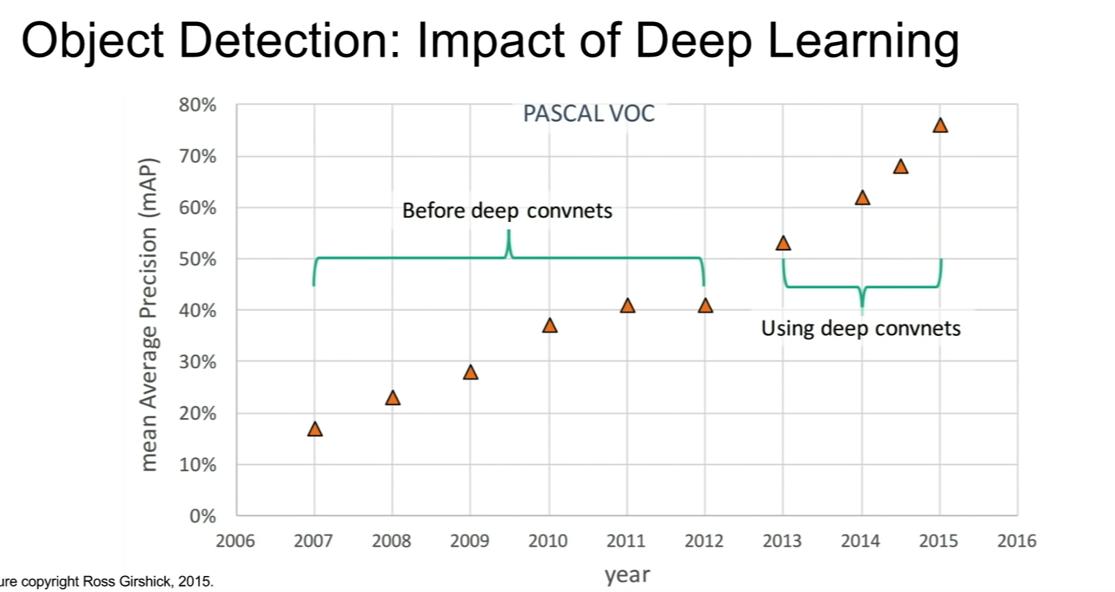
The period of 2006–2011 shows the utilization of traditional machine learning techniques for object detection; we can observe some stagnation in the mAP between 2010–2012. This stagnation trend changes with the onset of convnet(convolutional neural networks), we see an increase in mAP score to just above 75% in 2015.
The link below provides some information to get an overview of where the status of the current state of the art techniques.
All Rights Reserved for Richmond Alake
